AWS Well-Architected Framework: los pilares a dominar
AWS Well-Architected Framework es una de esas piezas que conviene entender bien desde el principio, porque no solo aparece en el examen CLF-C02, también representa una forma muy práctica de pensar cuando diseñas o revisas soluciones en la nube. No es un servicio que “enciendes” y ya está. Es un marco de buenas prácticas que AWS utiliza para ayudarte a revisar si una carga de trabajo está bien planteada desde varios ángulos: operación, seguridad, fiabilidad, rendimiento, coste y sostenibilidad.
El foco del marco es sencillo: una arquitectura cloud no es buena solo porque funcione. También debe poder operarse bien, protegerse, recuperarse de fallos, rendir correctamente, tener sus costes controlados y usar los recursos de forma responsable. Una aplicación puede estar funcionando hoy, pero estar mal diseñada si nadie la monitoriza, si no tiene backups, si está sobredimensionada o infradimensionada, si expone datos sensibles o si depende de una única zona de disponibilidad y no tolera errores o tienes puntos únicos de fallo.
Objetivos de aprendizaje
Entender qué representan excelencia operativa, seguridad, fiabilidad, eficiencia de rendimiento, optimización de costes y sostenibilidad.
Detectar qué pilar está evaluando una pregunta cuando habla de incidentes, cifrado, recuperación, latencia, gasto o eficiencia.
No confundir “barato” con bien optimizado, “rápido” con fiable o “gestionado” con seguro automáticamente.
Aplicar criterio de buenas prácticas sin entrar todavía en diseño avanzado de arquitecto.
1. Qué es AWS Well-Architected Framework
AWS Well-Architected Framework es un marco creado por AWS para ayudar a diseñar y operar cargas de trabajo de forma segura, eficiente, resiliente y rentable. Una carga de trabajo puede ser una aplicación, una plataforma, una web, una API, una base de datos, un sistema de análisis de datos o cualquier solución que preste un servicio de negocio.
El framework propone revisar la arquitectura desde seis pilares. Cada pilar responde a una pregunta distinta. Por ejemplo: ¿la operación está controlada?, ¿los datos están protegidos?, ¿la aplicación resiste fallos?, ¿los recursos elegidos son adecuados?, ¿estamos gastando más de lo necesario?, ¿estamos evitando desperdicio?
Para Cloud Practitioner no necesitas saber hacer una revisión Well-Architected completa, pero sí debes reconocer la intención de cada pilar. El examen puede preguntarte de forma directa “qué pilar se relaciona con X”, o de forma indirecta mediante un escenario.
2. Por qué este marco es importante en cloud
En un datacenter tradicional muchas decisiones son lentas y rígidas. Comprar hardware, ampliar capacidad o cambiar diseños puede llevar semanas o meses. En cloud puedes desplegar recursos en minutos, pero esa velocidad también puede generar errores: recursos sin control, costes innecesarios, permisos excesivos, arquitecturas frágiles o falta de monitorización.
Well-Architected ayuda a poner orden. No busca frenar la innovación, sino hacer que la adopción cloud sea sostenible y segura. Es como una revisión técnica periódica: no esperas a que todo falle para comprobar si tenías backups, alarmas, cifrado, límites de gasto o automatización.
Ejemplo sencillo
Una empresa migra una aplicación a AWS y todo parece funcionar. Pero solo usa una instancia EC2 en una única zona de disponibilidad, no tiene alarmas, las claves están compartidas entre varias personas y nadie revisa costes. La aplicación está “funcionando”, pero no está bien arquitectada. Well-Architected ayudaría a detectar esos riesgos.
3. Los seis pilares de Well-Architected
Los seis pilares son:
- Excelencia operativa: cómo operas, monitorizas, automatizas y mejoras tus sistemas.
- Seguridad: cómo proteges identidades, datos, sistemas y actividad.
- Fiabilidad: cómo una carga sigue funcionando y se recupera ante fallos.
- Eficiencia de rendimiento: cómo eliges y ajustas recursos para cumplir requisitos de rendimiento.
- Optimización de costes: cómo entregas valor evitando gasto innecesario.
- Sostenibilidad: cómo reduces desperdicio e impacto ambiental mediante eficiencia.
Un error habitual es estudiar estos pilares como definiciones aisladas. Es mejor relacionarlos con preguntas reales. Si el escenario habla de “recuperarse de una caída”, probablemente es fiabilidad. Si habla de “cifrado y permisos”, seguridad. Si habla de “instancias sobredimensionadas”, costes o rendimiento, según el contexto. Si habla de “automatizar operaciones y aprender de incidentes”, excelencia operativa.
4. Pilar de excelencia operativa
La excelencia operativa trata de operar sistemas de forma eficaz y mejorar continuamente. No basta con desplegar una aplicación; hay que saber cómo se despliega, cómo se monitoriza, cómo se corrigen errores, cómo se responde a incidentes y cómo se aprende de ellos.
En un entorno cloud, muchas tareas operativas se pueden automatizar. Por ejemplo, desplegar infraestructura con plantillas, crear alarmas, registrar logs, usar pipelines de despliegue, documentar procedimientos de operación y revisar qué ocurrió después de un incidente.
Para el examen, este pilar suele aparecer cuando el enunciado menciona operaciones, monitorización, automatización, runbooks, playbooks, mejora continua, despliegues repetibles o respuesta a incidentes.
Escenario tipo examen
Una empresa quiere reducir errores manuales en despliegues y tener procedimientos repetibles para operar su plataforma. El pilar más relacionado es excelencia operativa.
5. Buenas prácticas de excelencia operativa
- Automatizar cambios: reducir tareas manuales repetitivas y propensas a error.
- Usar métricas y logs: saber qué está pasando antes de que el usuario se queje.
- Preparar procedimientos: documentar cómo actuar ante eventos comunes.
- Hacer cambios pequeños y reversibles: reducir el impacto si algo sale mal.
- Aprender de incidentes: revisar causas y mejorar procesos.
Servicios relacionados en preguntas básicas: Amazon CloudWatch para métricas y alarmas, AWS CloudTrail para actividad de cuenta, AWS Systems Manager para operación, AWS CloudFormation para infraestructura como código y herramientas de CI/CD como CodePipeline o CodeDeploy.
6. Pilar de seguridad
El pilar de seguridad se centra en proteger información, sistemas e identidades. En AWS esto incluye controlar quién puede hacer qué, proteger datos en tránsito y en reposo, registrar actividad, aplicar mínimo privilegio y detectar posibles amenazas.
Para CLF-C02, seguridad está muy conectada con otros módulos: responsabilidad compartida, IAM, MFA, KMS, cifrado, CloudTrail, Security Groups, AWS WAF, GuardDuty, Macie y Security Hub.
La idea importante es que usar AWS no elimina tus responsabilidades de seguridad. AWS protege la infraestructura de la nube, pero tú debes configurar correctamente tus recursos, identidades, permisos, datos y aplicaciones.
Escenario tipo examen
Una empresa quiere limitar permisos para que los usuarios solo puedan realizar las acciones necesarias. Esto se relaciona con el pilar de seguridad y con el principio de mínimo privilegio.
7. Buenas prácticas de seguridad
- Aplicar mínimo privilegio: conceder solo los permisos necesarios.
- Usar MFA: especialmente en cuentas privilegiadas y usuario raíz.
- Cifrar datos: proteger información en reposo y en tránsito.
- Registrar actividad: usar trazabilidad para saber quién hizo qué y cuándo.
- Automatizar controles: detectar configuraciones débiles o exposiciones no deseadas.
- Separar responsabilidades: usar cuentas, roles y permisos de forma ordenada.
Si en una pregunta ves palabras como identidad, permisos, cifrado, datos sensibles, auditoría, actividad sospechosa, vulnerabilidades, MFA o acceso, probablemente estás cerca del pilar de seguridad.
8. Pilar de fiabilidad
La fiabilidad es la capacidad de una carga de trabajo para funcionar correctamente y recuperarse ante fallos. Una arquitectura fiable no asume que todo va a ir bien; asume que pueden fallar instancias, discos, zonas, redes o despliegues, y se prepara para ello.
En AWS, la fiabilidad suele apoyarse en diseño multi-AZ, balanceadores, Auto Scaling, backups, replicación, recuperación ante desastres y pruebas de recuperación.
Un punto clave para el examen: fiabilidad no es lo mismo que rendimiento. Una aplicación puede responder muy rápido cuando funciona, pero caer completamente si falla una única instancia. Eso sería buen rendimiento puntual, pero mala fiabilidad.
Escenario tipo examen
Una aplicación web corre en una única instancia EC2. La empresa quiere que siga disponible si falla una zona de disponibilidad. La respuesta se relaciona con fiabilidad: distribuir recursos en varias AZ, usar balanceador y diseñar tolerancia a fallos.
9. Buenas prácticas de fiabilidad
- Eliminar puntos únicos de fallo: no depender de un solo recurso crítico.
- Diseñar en varias zonas de disponibilidad: mejorar resiliencia ante fallos de una AZ.
- Usar Auto Scaling: ajustar capacidad y reemplazar instancias no saludables.
- Hacer backups: proteger datos frente a errores o fallos.
- Probar recuperación: validar que los planes funcionan realmente.
- Controlar cuotas y límites: evitar que una carga falle por límites no previstos.
Palabras clave de examen: alta disponibilidad, tolerancia a fallos, recuperación, backups, multi-AZ, failover, resiliencia, continuidad de negocio.
10. Pilar de eficiencia de rendimiento
La eficiencia de rendimiento trata de usar los recursos adecuados para cumplir requisitos de rendimiento. No significa elegir siempre lo más potente, ni tampoco lo más barato. Significa elegir lo que mejor encaja con la carga.
Por ejemplo, una aplicación con mucha lectura puede beneficiarse de caché. Una base de datos relacional puede ir mejor en RDS o Aurora que en una instancia autogestionada. Una aplicación con demanda variable puede usar Auto Scaling. Una carga serverless puede ser más adecuada para eventos que una flota permanente de servidores.
Este pilar también implica revisar y ajustar. Lo que hoy funciona puede quedarse corto mañana, o puede estar sobredimensionado y desperdiciar recursos.
Escenario tipo examen
Una aplicación tiene picos de tráfico y necesita ajustar capacidad automáticamente. Esto puede relacionarse con eficiencia de rendimiento y servicios como Auto Scaling, Elastic Load Balancing o arquitecturas serverless.
11. Buenas prácticas de eficiencia de rendimiento
- Elegir el tipo de recurso correcto: computación, almacenamiento y base de datos adecuados.
- Usar servicios gestionados: reducir carga operativa y aprovechar optimizaciones de AWS.
- Escalar según demanda: evitar capacidad fija cuando la carga varía.
- Usar caché cuando encaja: reducir latencia y carga en backend.
- Medir rendimiento: tomar decisiones con métricas, no con intuición.
Palabras clave de examen: latencia, rendimiento, escalado, tipo de instancia, caché, throughput, recursos adecuados, demanda variable.
12. Pilar de optimización de costes
La optimización de costes busca entregar valor de negocio al menor coste razonable. No significa usar siempre lo más barato, porque lo barato puede salir caro si rompe rendimiento, disponibilidad o seguridad. Significa evitar desperdicio y elegir el modelo económico adecuado.
En AWS pagas por uso, pero eso no garantiza ahorro automático. Si dejas recursos encendidos sin necesidad, eliges instancias demasiado grandes, guardas datos antiguos en clases caras o no revisas consumo, puedes gastar más de lo necesario.
Escenario tipo examen
Una empresa observa que muchas instancias están infrautilizadas. Quiere reducir gasto sin afectar al servicio. Esto se relaciona con optimización de costes: rightsizing, apagado de recursos innecesarios, Savings Plans, Reserved Instances, Cost Explorer y Trusted Advisor.
13. Buenas prácticas de optimización de costes
- Medir gasto: usar herramientas de visibilidad de costes.
- Asignar etiquetas: entender quién consume qué.
- Dimensionar correctamente: evitar recursos sobredimensionados.
- Elegir modelos de compra: On-Demand, Reserved Instances, Savings Plans o Spot según el caso.
- Usar clases de almacenamiento adecuadas: mover datos antiguos a clases más económicas.
- Eliminar recursos no usados: discos, snapshots, IPs, entornos temporales o instancias olvidadas.
Palabras clave de examen: Cost Explorer, AWS Budgets, Trusted Advisor, rightsizing, Savings Plans, Reserved Instances, Spot, etiquetado, gasto, presupuesto.
14. Pilar de sostenibilidad
La sostenibilidad busca minimizar el impacto ambiental de las cargas cloud. En el examen puede aparecer menos que seguridad o costes, pero debes conocerlo porque ya forma parte de los seis pilares.
Sostenibilidad en cloud no significa solo “usar un proveedor eficiente”. El cliente también influye. Si ejecutas recursos sobredimensionados, mantienes entornos innecesarios encendidos o guardas datos sin valor durante años, estás desperdiciando capacidad.
Muchas buenas prácticas de sostenibilidad se parecen a las de optimización de costes: usar recursos eficientes, ajustar capacidad, eliminar desperdicio, usar servicios gestionados y medir consumo. La diferencia es el enfoque: costes mira el gasto económico; sostenibilidad mira el uso responsable de recursos y el impacto ambiental.
Escenario tipo examen
Una empresa quiere reducir recursos infrautilizados y eliminar datos que ya no necesita para disminuir desperdicio. Puede relacionarse con sostenibilidad, además de optimización de costes.
15. Buenas prácticas de sostenibilidad
- Evitar sobreaprovisionamiento: no reservar más capacidad de la necesaria.
- Eliminar recursos sin uso: apagar entornos temporales y limpiar datos obsoletos.
- Usar servicios gestionados: aprovechar infraestructura compartida y optimizada.
- Escalar dinámicamente: consumir capacidad cuando se necesita.
- Optimizar almacenamiento: aplicar lifecycle y retención adecuada.
16. Tabla de decisión rápida por pilar
| Pilar | Qué pregunta responde | Pistas típicas en CLF-C02 |
|---|---|---|
| Excelencia operativa | ¿Cómo opero, monitorizo, automatizo y mejoro la carga? | Runbooks, automatización, métricas, despliegues, incidentes, mejora continua. |
| Seguridad | ¿Cómo protejo identidades, datos, sistemas y actividad? | IAM, MFA, cifrado, KMS, CloudTrail, mínimo privilegio, datos sensibles. |
| Fiabilidad | ¿Cómo sigue funcionando la carga ante fallos? | Multi-AZ, backups, failover, recuperación, resiliencia, tolerancia a fallos. |
| Eficiencia de rendimiento | ¿Cómo elijo recursos adecuados para cumplir requisitos técnicos? | Latencia, escalado, caché, tipos de instancia, rendimiento, demanda variable. |
| Optimización de costes | ¿Cómo entrego valor evitando gasto innecesario? | Rightsizing, Budgets, Cost Explorer, Savings Plans, Reserved Instances, Spot. |
| Sostenibilidad | ¿Cómo reduzco desperdicio e impacto ambiental? | Recursos infrautilizados, eficiencia, eliminación de datos innecesarios, servicios gestionados. |
17. Diferencias que suelen confundir
Fiabilidad no es lo mismo que rendimiento
Rendimiento habla de que una aplicación responda rápido y use recursos adecuados. Fiabilidad habla de que siga funcionando y pueda recuperarse ante fallos. Una aplicación puede ser rápida, pero poco fiable si depende de una sola instancia.
Coste no es lo mismo que sostenibilidad
Ambos pilares pueden recomendar reducir recursos desperdiciados, pero el enfoque no es exactamente igual. Coste se centra en valor económico. Sostenibilidad se centra en impacto y eficiencia de uso de recursos.
Seguridad no es lo mismo que cumplimiento
Seguridad protege sistemas, identidades y datos. Cumplimiento se relaciona con requisitos normativos, auditorías, evidencias y estándares. Están conectados, pero no son idénticos.
Excelencia operativa no es solo monitorizar
Monitorizar es una parte. También incluye automatizar, documentar, desplegar de forma segura, aprender de incidentes y mejorar continuamente.
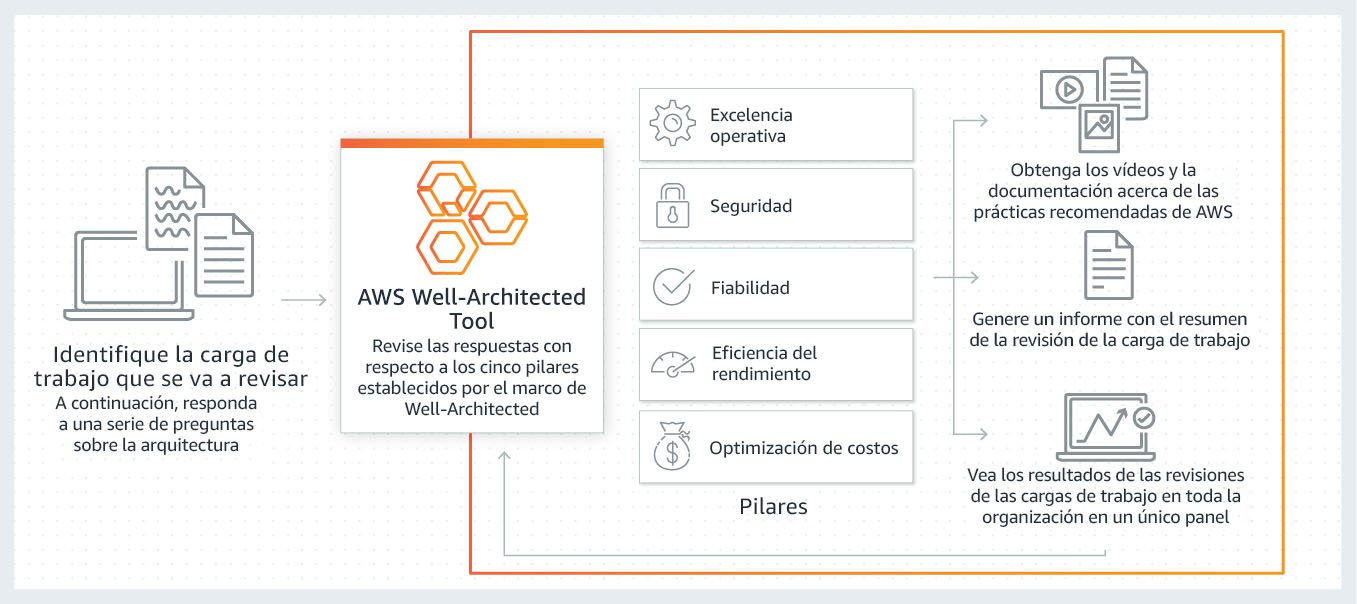
18. AWS Well-Architected Tool
AWS ofrece AWS Well-Architected Tool, una herramienta que permite revisar cargas de trabajo siguiendo el framework. Ayuda a documentar decisiones, identificar riesgos y recibir recomendaciones de mejora.
Para CLF-C02, no necesitas saber usarla paso a paso. Basta con reconocer que existe una herramienta de AWS para revisar workloads frente a las buenas prácticas de Well-Architected.
Escenario tipo examen
Una empresa quiere evaluar una carga de trabajo frente a buenas prácticas de arquitectura AWS e identificar riesgos. La respuesta puede apuntar a AWS Well-Architected Framework o AWS Well-Architected Tool.
19. Cómo razonar preguntas del examen
Cuando una pregunta mencione Well-Architected, busca primero el problema real. No te fijes solo en palabras sueltas. Pregúntate:
- ¿El problema es operar mejor, automatizar o responder a incidentes? Entonces piensa en excelencia operativa.
- ¿El problema es proteger datos, usuarios, permisos o actividad? Entonces piensa en seguridad.
- ¿El problema es seguir funcionando ante fallos? Entonces piensa en fiabilidad.
- ¿El problema es latencia, capacidad o elección de recursos? Entonces piensa en eficiencia de rendimiento.
- ¿El problema es gasto innecesario o recursos sobredimensionados? Entonces piensa en optimización de costes.
- ¿El problema es desperdicio de recursos o impacto ambiental? Entonces piensa en sostenibilidad.
20. Escenarios prácticos de repaso
Escenario 1: despliegues manuales con errores
Un equipo despliega cambios manualmente y cada despliegue genera incidencias. El pilar más relacionado es excelencia operativa, porque se necesita automatización, procedimientos repetibles y mejora continua.
Escenario 2: permisos demasiado amplios
Varios usuarios tienen permisos de administrador aunque solo necesitan leer recursos. El pilar principal es seguridad, porque se debe aplicar mínimo privilegio.
Escenario 3: aplicación en una sola AZ
Una aplicación crítica depende de una única zona de disponibilidad. El pilar principal es fiabilidad, porque hay un punto único de fallo.
Escenario 4: latencia elevada
Una aplicación responde lentamente por falta de caché o por recursos inadecuados. El pilar principal puede ser eficiencia de rendimiento.
Escenario 5: gasto elevado por recursos infrautilizados
La empresa paga por instancias que apenas se usan. El pilar principal es optimización de costes, y se puede aplicar rightsizing o apagado programado.
Escenario 6: entornos olvidados encendidos
Hay entornos de prueba encendidos todo el tiempo sin uso real. Esto afecta a costes y también a sostenibilidad por desperdicio de recursos.
21. Errores típicos
- Memorizar los pilares sin entender escenarios reales.
- Confundir fiabilidad con rendimiento: rápido no significa resiliente.
- Creer que optimización de costes significa usar siempre lo más barato.
- Olvidar que seguridad atraviesa todos los servicios y no desaparece por usar servicios gestionados.
- Pensar que sostenibilidad es solo responsabilidad de AWS y no del diseño del cliente.
- Confundir Well-Architected Framework con un servicio aislado obligatorio para desplegar recursos.
- Asumir que una arquitectura está bien solo porque funciona actualmente.
- No revisar cargas de trabajo después de cambios importantes.
- No medir: sin métricas, costes, logs y revisiones es difícil mejorar.
Test del módulo · 12 preguntas
- Fiabilidad
- Sostenibilidad
- Facturación consolidada
- Marketplace
Ver respuesta y explicación
Respuesta: A. La fiabilidad se centra en que una carga funcione correctamente y pueda recuperarse ante fallos.
- Seguridad
- Optimización de costes
- Sostenibilidad
- Alcance global
Ver respuesta y explicación
Respuesta: A. Mínimo privilegio, cifrado y trazabilidad pertenecen al pilar de seguridad.
- Optimización de costes
- Residencia de datos
- IAM Identity Center
- AWS Artifact
Ver respuesta y explicación
Respuesta: A. Rightsizing y reducción de gasto innecesario se asocian a optimización de costes.
- Excelencia operativa
- Facturación
- DNS
- Almacenamiento de objetos
Ver respuesta y explicación
Respuesta: A. Excelencia operativa cubre operación, automatización, observabilidad y mejora continua.
- Sostenibilidad
- Uso obligatorio de una única AZ
- Bloqueo de cuenta raíz
- Un dominio DNS
Ver respuesta y explicación
Respuesta: A. La sostenibilidad busca reducir desperdicio y usar recursos de forma eficiente.
- Fiabilidad
- Rendimiento
- Documentación
- Facturación consolidada
Ver respuesta y explicación
Respuesta: A. El problema no es velocidad, sino falta de resiliencia ante fallos.
- Eficiencia de rendimiento
- AWS Artifact
- Consolidated billing
- Global Accelerator
Ver respuesta y explicación
Respuesta: A. La eficiencia de rendimiento trata de elegir recursos adecuados para cumplir requisitos técnicos.
- AWS Well-Architected Tool
- AWS Budgets
- Amazon Polly
- AWS Snowball
Ver respuesta y explicación
Respuesta: A. AWS Well-Architected Tool ayuda a revisar workloads frente al framework.
- Seguridad
- Sostenibilidad
- Costes
- Marketplace
Ver respuesta y explicación
Respuesta: A. La trazabilidad y auditoría ayudan a reforzar el pilar de seguridad.
- Busca entregar valor evitando gasto innecesario.
- Siempre obliga a usar el recurso más barato.
- Solo aplica al Free Tier.
- No requiere medir consumo.
Ver respuesta y explicación
Respuesta: A. Optimizar costes no significa usar siempre lo más barato, sino maximizar valor y reducir desperdicio.
- Fiabilidad
- Sostenibilidad
- Soporte técnico
- Facturación
Ver respuesta y explicación
Respuesta: A. Multi-AZ, backups y failover son patrones de resiliencia y recuperación.
- Optimización de costes y sostenibilidad
- Solo seguridad física
- Solo cumplimiento legal
- Solo soporte Enterprise
Ver respuesta y explicación
Respuesta: A. Apagar recursos no usados reduce gasto y también desperdicio de capacidad.
Resumen final
AWS Well-Architected Framework te ayuda a revisar si una carga de trabajo está bien diseñada más allá de que “funcione”. Sus seis pilares cubren las grandes áreas que una solución cloud debe cuidar: operar bien, proteger, resistir fallos, rendir adecuadamente, controlar costes y reducir desperdicio.
Para el examen CLF-C02, no intentes memorizar definiciones largas. Aprende a detectar la pista del escenario. Si habla de permisos y cifrado, seguridad. Si habla de fallos y recuperación, fiabilidad. Si habla de automatización y operaciones, excelencia operativa. Si habla de latencia o recursos adecuados, eficiencia de rendimiento. Si habla de gasto, optimización de costes. Si habla de desperdicio e impacto, sostenibilidad.